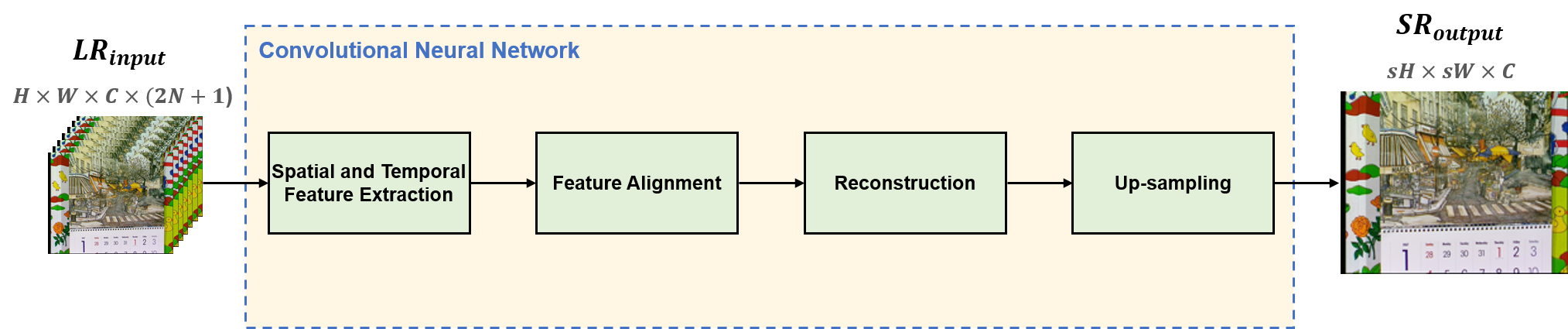
Video Super-Resolution (VSR)
Super-resolution (SR) is a traditional problem in low-level vision field. The goal of SR is to reconstruct a high-resolution (HR) image from the corresponding low-resolution (LR) image.
Compared to single image super-resolution (SISR), video super-resolution (VSR) uses additional adjacent frames to reconstruct a HR video frame.
The key challenge for VSR lies in the effective exploitation of spatial correlation in an intra-frame and temporal dependency between consecutive frames.
With the success of the convolutional neural networks (CNN) in computer vision tasks, CNN has also been successfully applied to VSR task.
The VSR technique is widely used in various computer vision applications such as medical, satellite, surveillance, and low-bitrate media imaging systems. Moreover, with the growth of display industries, the SR has become more crucial in recent years.
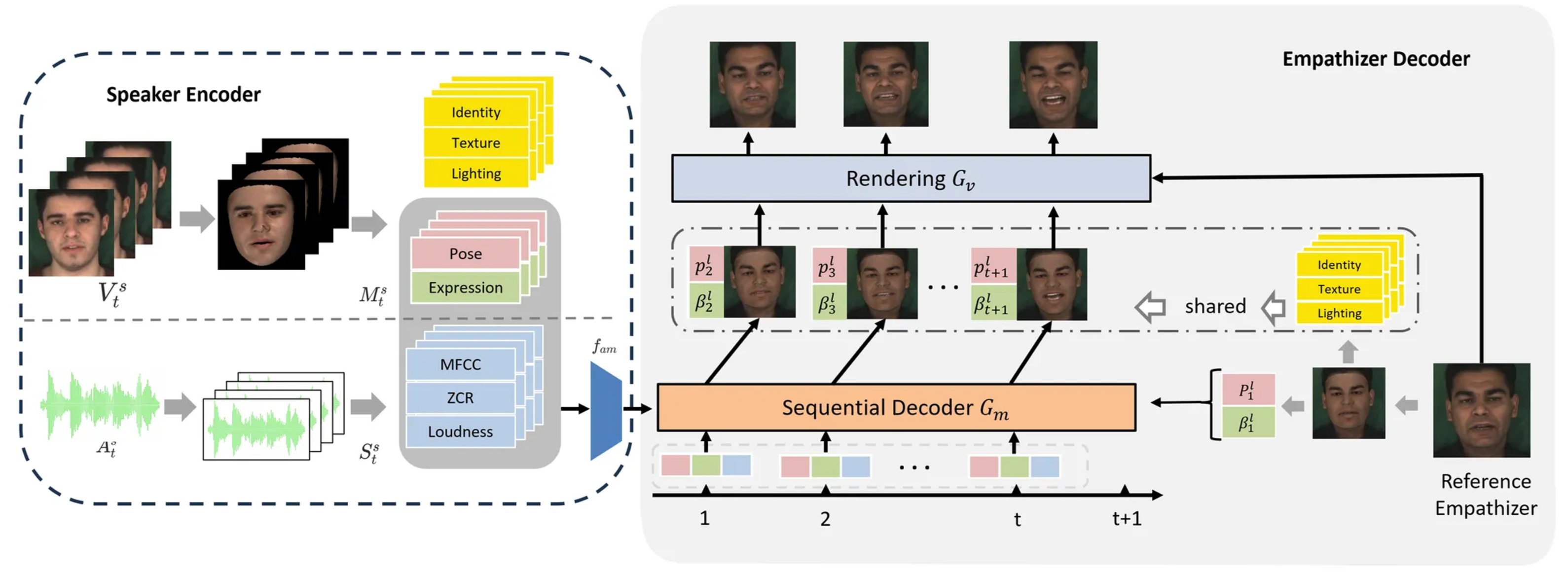
Generative Models for Multimedia Synthesis
Generative models have revolutionized multimedia content creation by learning complex data distributions and generating high-quality synthetic outputs. Our research focuses on empathetic response generation and video editing applications using diffusion models and transformer architectures.
We develop empathetic response generation systems that recognize and respond to emotional states through multimodal inputs including text, audio, and visual data. Our facial expression recognition (FER) framework identifies human emotions from video sequences, enabling applications in healthcare monitoring, intelligent tutoring systems, and social robotics.
We also investigate video editing and enhancement techniques that achieve high-quality synthesis while maintaining temporal consistency. Our research includes motion control through optical flow-based guidance and camera parameter conditioning, as well as video enhancement methods using diffusion transformers with LoRA fine-tuning to improve visual quality, restore degraded videos, and support various editing tasks.

DeepFake Detection for Fake Media
DeepFakes (a portmanteau of “Deeplearning” and “fake”) are synthetic media in which a person in an existing image or video is replaced with someone else’s likeness.
We detect deepfakes by using deep learning model which contains probability that the video is real or fake.
We use DFDC-Full dataset by Facebook-AI and are investigating to design a new scheme based on Vision Transformer network and some modifications as training model.
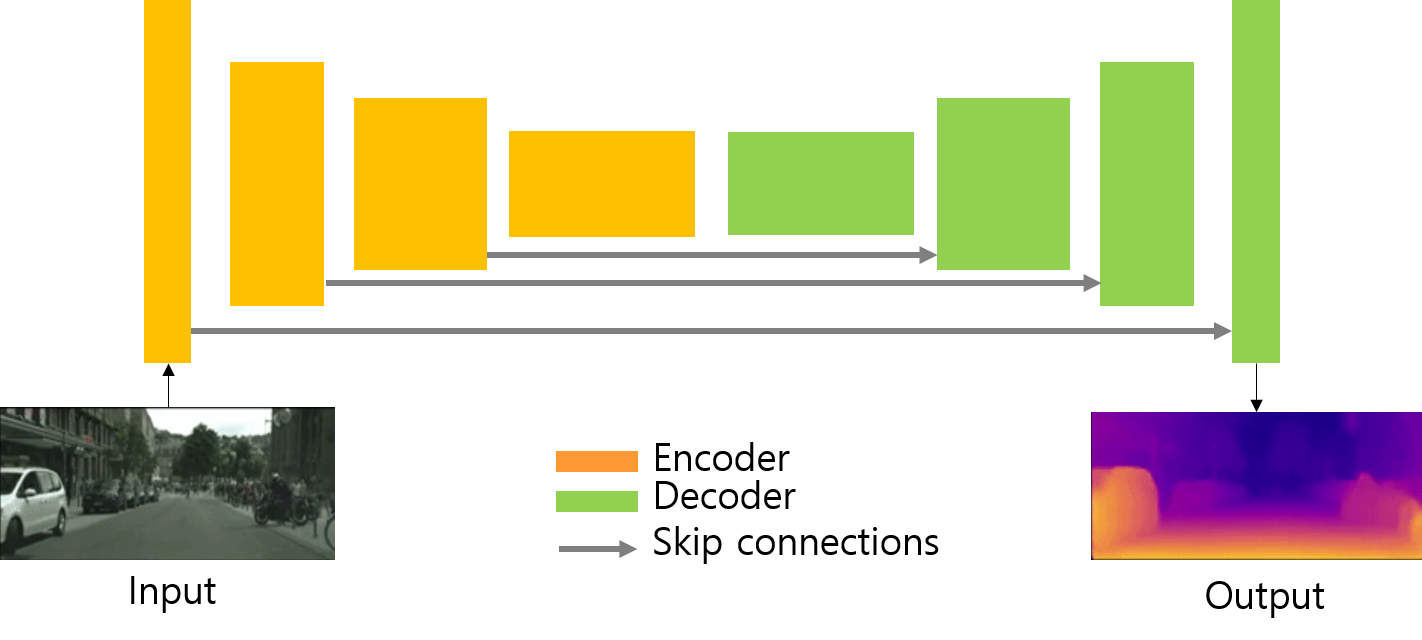
Depth Estimation
Learning geometry has been researched as one of the most topics in computer vision over the last few years.
The core idea behind reprojection losses is using epipolar geometry to relate corresponding points in multi-view stereo imager.
An autonomous vehicle is one that can drive, accelerate, steer, brake and park on its own, without requiring the driver assistance. Depth estimation is applied to understand the extent of the object and each pixel of it.
Autostereoscopic displays are advanced systems, which do not require glasses. Here, 2 or more views are displayed at the same time. Any pixel of the image can be projected into depth image and then projected back onto an arbitrary virtual camera plane, creating a virtual image.

Object Detection
Object detection predicts the probability of multiple objects categories and its position in an image.
It combines multi-label classification and bounding box regression to jointly optimize two related tasks.
Moreover, 3D Object Detection incorporates depth information to not only detect and recognize objects but also predict their positions in a three-dimensional space.
There are many applications to object detection techniques such as autonomous driving, robotics, object tracking and optical character recognition (OCR).
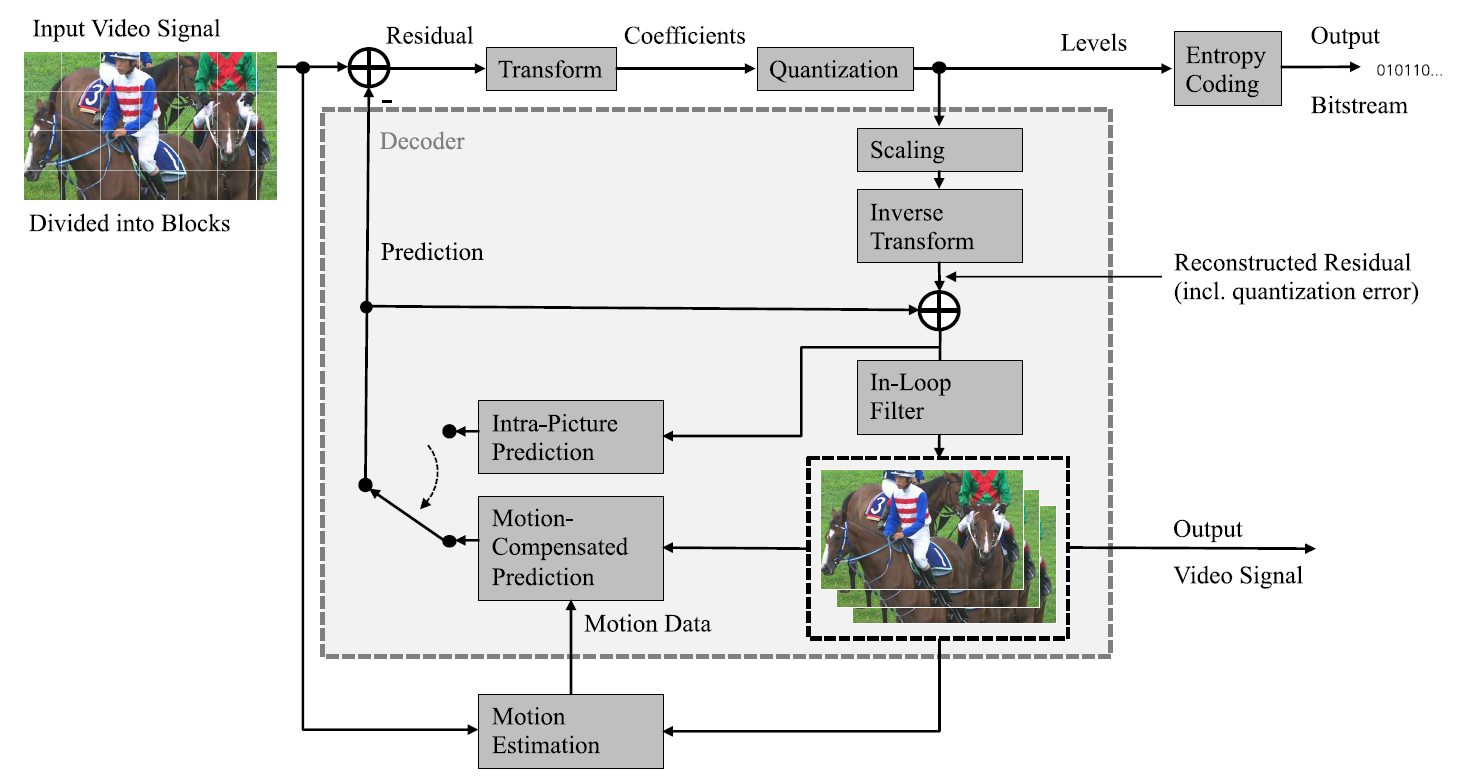
Video Coding Theory and Standard Technology
Mathematical modeling and theoretical studies such as signal transformation and signal filtering are carried out for improving video coding efficiency.
Versatile Video Coding (VVC) is a new state of the art video compression standard that is going to standardize, as the next generation of High Efficiency Video Coding (HEVC) standard.
The primary reason for permanent improvements in video compression is emerging higher resolution video (e.g., 8K UHD) and many kind of video services such as 360° omnidirectional immersive video and high-dynamic-range (HDR) video.
As in most preceding standards, VVC has a block-based hybrid coding architecture, combining inter-picture and intra-picture prediction and transform coding with entropy coding.
Deep Neural Network (DNN)-based Video Coding
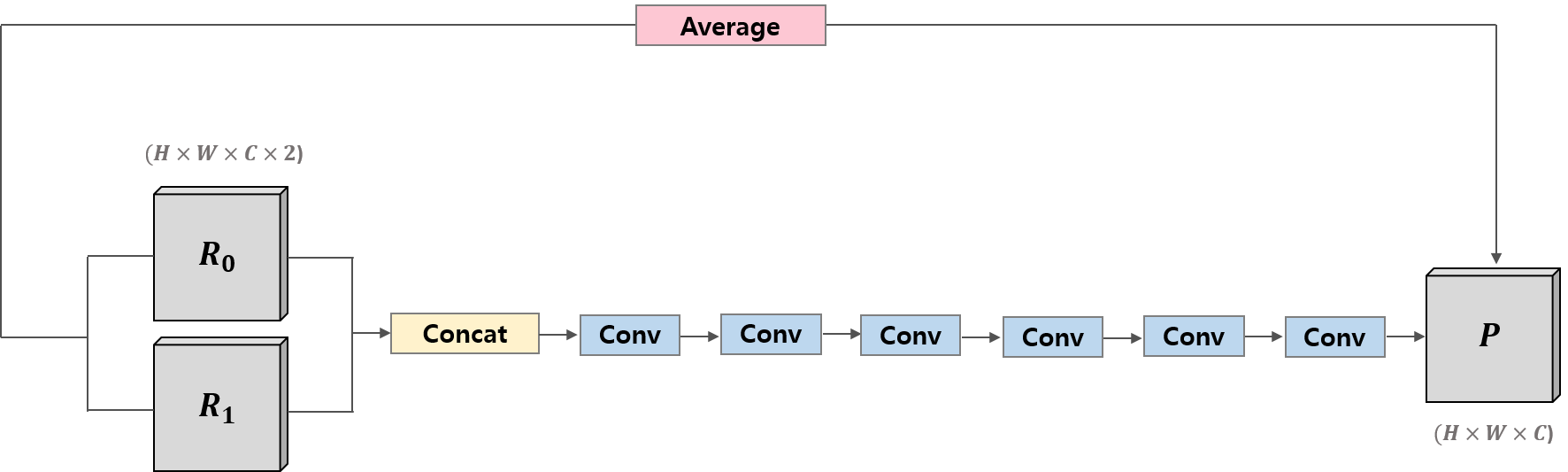
a. Convolutional Neural Network-Based Bi-Prediction
Mathematical modeling and theoretical studies such as signal transformation and signal filtering are carried out for improving video coding efficiency.
Versatile Video Coding (VVC) is a new state of the art video compression standard that is going to standardize, as the next generation of High Efficiency Video Coding (HEVC) standard.
The primary reason for permanent improvements in video compression is emerging higher resolution video (e.g., 8K UHD) and many kind of video services such as 360° omnidirectional immersive video and high-dynamic-range (HDR) video.
As in most preceding standards, VVC has a block-based hybrid coding architecture, combining inter-picture and intra-picture prediction and transform coding with entropy coding.

b. Convolutional Neural Network-Based Fast Inter Mode Decision
Fast coding unit (CU) split mode decision for Versatile Video Coding (VVC) Inter prediction.
The latest VVC codec adopts quadtree with nested multi-type tree (QTMT) the quad-tree with Multi-type tree (QTMT) structure as a partition structure.
To decide split mode and split type in fast, we utilize light-weight convolutional neural network (CNN).
The original CU image as well as temporal information from VVC encoder are used for training CNN, and the network inferences split mode.